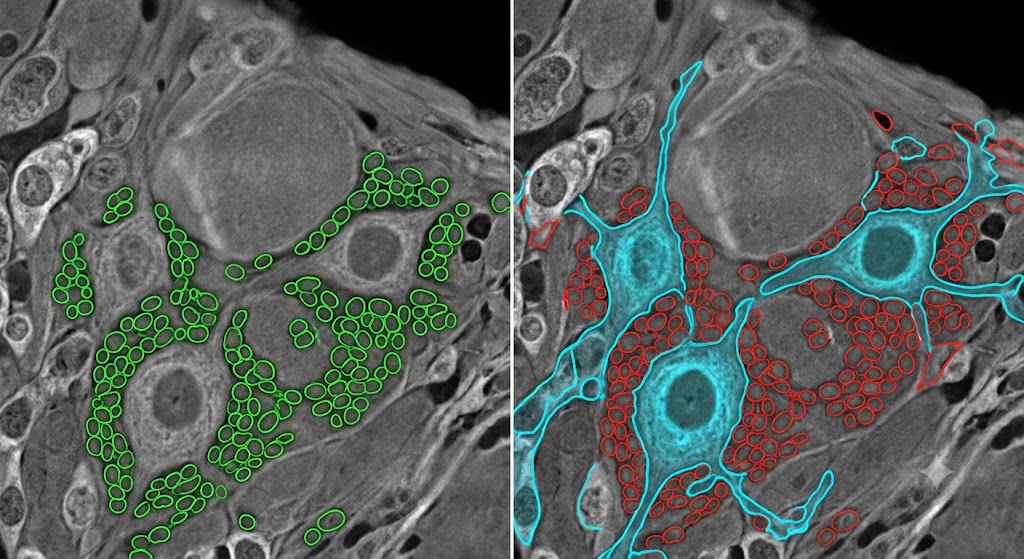
The media Bio-IT World recently published a brief note by Karan Patel, an Image Analysis Scientist at Bio-Techne who develops deep learning pipelines for spatial omics in preclinical research. He states that pretrained AI models frequently fail in spatial biology because their training data lacks real world structural complexity. While standard architectures excel on clean benchmarks, they routinely miss critical, large cell populations, like primary sensory neurons in dorsal root ganglion tissue, by mistaking them for background. The actual bottleneck isn't the architecture; it is the data it was taught on.
To succeed, a model must be trained specifically on the edge cases that break traditional approaches: tissue areas with inconsistent staining, large neurons tightly adjacent to SGC clusters, and large neurons with gradual intensity borders at the edges. Drawing over 500 annotations from morphologically difficult examples ensures the model learns from biological complexity rather than idealized conditions. Models trained only on clean, uniform tissue routinely fail when staining conditions vary in production.
Ultimately, high quality annotation requires domain expertise. It is the core scientific decision determining whether an AI pipeline succeeds or fails in production.